Conjuntos de caracteres HTML
Aprende sobre conjuntos de caracteres HTML — ASCII, ANSI, ISO-8859-1 y UTF-8 — y cómo declarar la codificación con la etiqueta meta charset.
Un conjunto de caracteres (o codificación de caracteres) es la asignación que indica al navegador cómo convertir los bytes sin procesar de un archivo en las letras, dígitos, signos de puntuación y símbolos que se ven en pantalla. El navegador debe saber qué conjunto de caracteres utiliza una página para mostrarla correctamente.
UTF-8 es la codificación de caracteres predeterminada para HTML5. No siempre fue así. ASCII fue el primero, e ISO-8859-1 fue el conjunto de caracteres predeterminado desde HTML 2.0 hasta HTML 4.01. Cada uno de esos conjuntos más antiguos solo podía representar un rango limitado de caracteres, lo que causaba problemas para el texto en idiomas distintos al inglés. Cuando UTF-8 llegó junto con HTML5 y XML, resolvió la mayoría de esos problemas al cubrir prácticamente todos los sistemas de escritura en una sola codificación.
Esta página recorre los principales conjuntos de caracteres que puedes encontrar — ASCII, ANSI, ISO-8859-1 y Unicode/UTF-8 — y muestra cómo declarar la codificación tanto en HTML moderno como en HTML heredado.
Qué ocurre cuando falta la codificación o hay una discrepancia
Si una página no declara su codificación, o declara una que no coincide con cómo se guardó realmente el archivo, el navegador lo adivina — y a menudo se equivoca. El síntoma más común es el mojibake: texto ilegible donde las letras acentuadas, las comillas tipográficas o los emoji se convierten en cadenas como é o ’.
Además de verse roto, un charset no declarado o con discrepancias puede suponer un problema de seguridad: algunos ataques se basan en que el navegador interprete los bytes bajo una codificación diferente a la que pretendía el autor (por ejemplo, ataques de cross-site scripting basados en UTF-7). Declarar una codificación única y explícita desde el principio elimina esa ambigüedad. La opción moderna y segura es servir siempre el contenido como UTF-8 y declararlo claramente con <meta charset="UTF-8">.
ASCII
ASCII fue el primer estándar de codificación de caracteres, también llamado conjunto de caracteres. Sus siglas provienen de American Standard Code for Information Interchange.
Para cada carácter almacenable, ASCII definió un número único que admite el alfabeto en mayúsculas y minúsculas (a-z, A-Z), los números del 0 al 9 y un puñado de caracteres especiales. Está basado en el alfabeto inglés y codifica 128 caracteres en un entero binario de 7 bits. Por ejemplo, la letra mayúscula A tiene el código 65 (binario 01000001), a es 97 y el dígito 0 es 48. Esto funciona porque toda la información de los ordenadores se almacena en última instancia como unos y ceros binarios en la electrónica.
A continuación, puedes ver una tabla ASCII que asigna a cada carácter su código decimal, hexadecimal y binario.
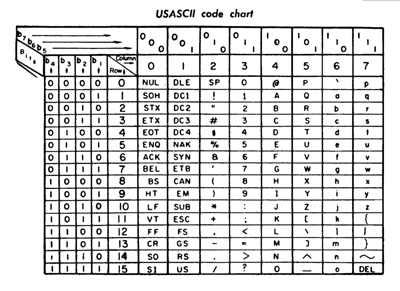
La mayor limitación de ASCII es que no dispone de letras no inglesas ni de caracteres acentuados. Sigue en uso hoy en día, especialmente en ordenadores de gran capacidad (mainframes), y constituye la base sobre la que se construyen las codificaciones posteriores (incluida UTF-8).
Haz clic aquí para ver más sobre ASCII.
ANSI
ANSI, también denominado Windows-1252, fue el conjunto de caracteres predeterminado de Windows hasta Windows 95. Es una extensión de ASCII que añade caracteres internacionales. Admitía 256 caracteres usando un byte completo (8 bits).
ANSI fue compatible con todos los navegadores desde que se anunció como el conjunto de caracteres predeterminado de Windows.
ISO-8859-1
ISO-8859-1 se convirtió en la codificación de caracteres predeterminada en HTML 2.0, ya que la mayoría de los países utilizan caracteres distintos de los de ASCII. También es una extensión de ASCII, al igual que ANSI, y añade caracteres internacionales. ISO-8859-1 también usa un byte completo para representar el doble de caracteres que ASCII.
Haz clic aquí para ver más sobre ISO-8859-1.
Codificación predeterminada en HTML 4
En HTML 4, la codificación se declaraba con una etiqueta <meta> de tipo http-equiv. Como ISO-8859-1 era la predeterminada, así es como se indicaba explícitamente:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1" />Cambiar el charset en HTML 4
Si una página HTML 4 necesita una codificación de caracteres distinta de la predeterminada ISO-8859-1 — por ejemplo, ISO-8859-8 para el hebreo — simplemente se cambia el valor de charset en la misma etiqueta <meta>:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-8" />La mayoría de los procesadores HTML 4 también entendían UTF-8, lo que allanó el camino para que se convirtiera en el estándar en HTML5.
La forma en HTML5
HTML5 reemplazó la forma verbosa de http-equiv por un atributo corto y dedicado:
<meta charset="UTF-8" />Coloca esta etiqueta lo antes posible dentro del elemento <head> — idealmente como primer hijo — para que el navegador lea la codificación antes de analizar cualquier contenido de texto.
Unicode UTF-8
UTF-8 es la codificación de caracteres predeterminada — y recomendada — para HTML5.
Dado que los conjuntos de caracteres descritos anteriormente están limitados a un máximo de 256 caracteres, el Consorcio Unicode desarrolló el Estándar Unicode, un catálogo único que asigna un número único (llamado punto de código) a casi todos los caracteres, signos de puntuación y símbolos que se usan en el mundo — en miles de idiomas, además de emoji y símbolos matemáticos. UTF-8 es la forma más popular de codificar esos puntos de código como bytes.
Por qué UTF-8 es el estándar moderno
Tres propiedades hacen de UTF-8 la elección natural para la web:
- Cobertura universal. Puede representar cualquier punto de código Unicode, de modo que una sola página puede mezclar inglés, árabe, chino y emoji sin cambiar de codificación.
- Compatible con ASCII. Los primeros 128 puntos de código se codifican exactamente con los mismos bytes individuales que ASCII. Cualquier archivo ASCII puro ya es UTF-8 válido, lo que significa que décadas de texto antiguo y herramientas siguen funcionando.
- Eficiencia de ancho variable. Los caracteres comunes ocupan solo un byte, mientras que los menos comunes usan dos, tres o cuatro bytes solo cuando es necesario. Los documentos mayormente en inglés se mantienen compactos, pero nada queda excluido.
En HTML, el atributo charset de la etiqueta <meta> especifica la codificación:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>UTF-8 example</title>
</head>
<body>
<p>English, Русский, 中文, العربية, 😀</p>
</body>
</html>Mantén <meta charset="UTF-8"> como lo primero dentro del <head> (dentro de los primeros 1024 bytes del documento). Si aparece demasiado tarde, el navegador puede comenzar a analizar el texto con la codificación incorrecta antes de ver la declaración.
Caracteres multibyte y el BOM
En UTF-8, un solo carácter puede abarcar varios bytes. Por ejemplo, el signo del euro € (punto de código Unicode U+20AC) se almacena como los tres bytes E2 82 AC, mientras que un carácter como A sigue ocupando solo un byte. Esto es lo que significa "ancho variable" en la práctica.
También puedes encontrarte con el BOM (Byte Order Mark), una secuencia opcional e invisible de bytes (EF BB BF para UTF-8) al inicio de un archivo que indica su codificación. El BOM no es obligatorio para UTF-8 y generalmente es mejor omitirlo en HTML, ya que un <meta charset="UTF-8"> explícito ya cumple esa función y un BOM inesperado puede ocasionar problemas de renderizado en algunas ocasiones.
Para insertar símbolos específicos sin preocuparse por cómo guarda el archivo tu editor, también puedes usar entidades HTML con nombre o numéricas (por ejemplo, € para €).
Todos los procesadores HTML5 admiten UTF-8. Ten en cuenta que los procesadores XML requieren estrictamente UTF-8 o UTF-16.